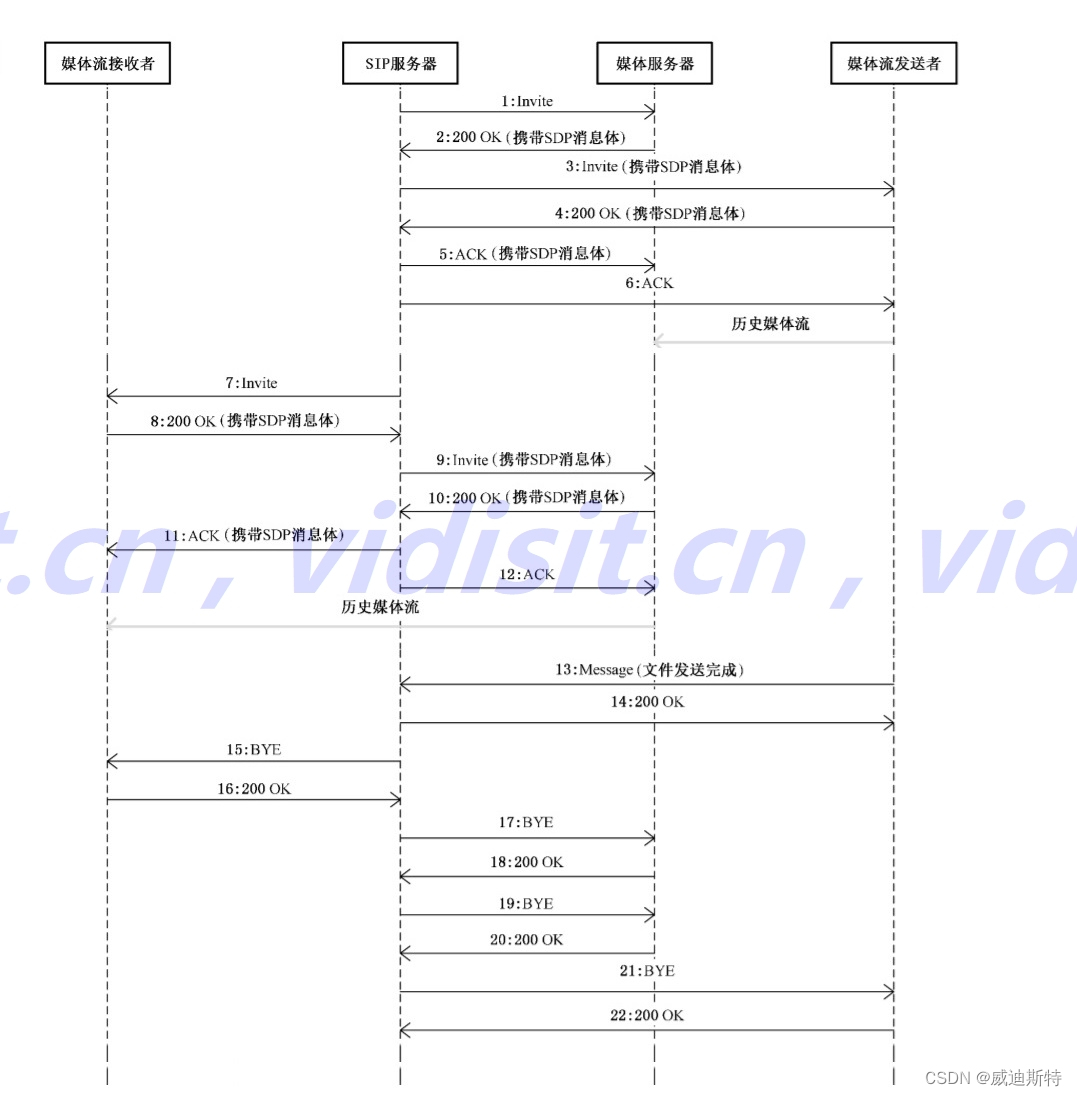
# 导入相关模块
import numpy as np
from collections import Counter
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.utils import shuffle
def load_data():
iris = datasets.load_iris()
# 打乱数据后的数据和标签
X, y = shuffle(iris.data, iris.target, random_state=13)
# 数据转换为 flout32 格式
X = X.astype(np.float32)
# 简单划分训练集和测试集, 训练样本 - 测试样本比例为 7:3
offset = int(X.shape[0] * 0.7)
X_train, y_train = X[:offset], y[:offset]
X_test, y_test = X[offset:], y[offset:]
# 将标签转换为竖向量
y_train = y_train.reshape((-1, 1))
y_test = y_test.reshape((-1, 1))
return X_train, X_test, y_train, y_test
def compute_distances(X, X_train):
"""
定义欧氏距离函数
X: 测试样本实例矩阵
X_train: 训练样本实例矩阵
"""
# 测试实例样本
num_test = X.shape[0]
# 训练实例样本量
num_train = X_train.shape[0]
# 基于训练和测试维度的欧氏距离初始化
dists = np.zeros((num_test, num_train))
# 测试样本鱼训练样本的矩阵点乘
M = np.dot(X, X_train.T)
# 测试样本矩阵平方
te = np.square(X).sum(axis=1)
# 训练样本矩阵平方
tr = np.square(X_train).sum(axis=1)
# 计算欧式距离
dists = np.sqrt(-2 * M + tr + np.matrix(te).T)
return dists
def predict_labels(y_train, dists, k=1):
"""
定义预测函数
:param y_train: 训练集标签
:param dists: 测试集与训练集之间的欧氏距离矩阵
:param k: k值
:return: 测试集预测结果
"""
# 测试样本量
num_test = dists.shape[0]
# 初始化测试集预测结果
y_pred = np.zeros(num_test)
# 遍历
for i in range(num_test):
# 初始化最近邻列表
closest_y = []
# 按 欧式距离矩阵排序后取索引, 并用训练集标签按排序后的索引取值
# 最后展平列表
# 注意 np.argsort 函数的用法
labels = y_train[np.argsort(dists[i, :])].flatten()
# 取最近的k个值
closest_y = labels[0:k]
# 对最近的k个值进行计数统计
# 这里注意 collections 模块中的计数器 Counter 的用法
c = Counter(closest_y)
# 取计数最多的那个类别
y_pred[i] = c.most_common(1)[0][0]
return y_pred
if __name__ == '__main__':
# 导入 sklearn iris 数据集
X_train, X_test, y_train, y_test = load_data()
dists = compute_distances(X=X_test, X_train=X_train)
y_test_pred = predict_labels(y_train=y_train, dists=dists, k=1)
y_test_pred = y_test_pred.reshape((-1, 1))
# 找出预测正确的实例
num_correct = np.sum(y_test_pred == y_test)
# 计算分类准确率
accuracy = float(num_correct) / X_test.shape[0]
print('KNN Accuracy based on NumPy: ' + str(accuracy))
# 用五折交叉验证寻找最优 k值
# 五折
num_folds = 5
# 候选 k 值
k_choices = [1, 3, 5, 8, 10, 12, 15, 20, 50, 100]
X_train_folds = []
y_train_folds = []
# 训练数据划分
X_train_folds = np.array_split(X_train, num_folds)
# 训练标签划分
y_train_folds = np.array_split(y_train, num_folds)
k_to_accuracies = {}
# 表里所有候选k值
for k in k_choices:
# 五折遍历
for fold in range(num_folds):
# 为 传入的训练集单独划分出一个验证集作为测试集
validation_X_test = X_train_folds[fold]
validation_y_test = y_train_folds[fold]
temp_X_train = np.concatenate(X_train_folds[:fold] + X_train_folds[fold+1:])
temp_y_train = np.concatenate(y_train_folds[:fold] + y_train_folds[fold+1:])
# 计算距离
temp_dists = compute_distances(X=validation_X_test, X_train=temp_X_train)
temp_y_test_pred = predict_labels(temp_y_train, temp_dists, k=k)
temp_y_test_pred = temp_y_test_pred.reshape((-1, 1))
# 查看分类准确率
num_correct = np.sum(temp_y_test_pred == validation_y_test)
num_test = validation_X_test.shape[0]
accuracy = float(num_correct) / num_test
k_to_accuracies[k] = k_to_accuracies.get(k, []) + [accuracy]
for k in sorted(k_to_accuracies):
for accuracy in k_to_accuracies[k]:
print(f'k = {k}, accuracy = {accuracy}')
# 打印不同k值, 不同折数下的分类准确率
for k in k_choices:
# 取出第k个k值的分类准确率
accuracies = k_to_accuracies[k]
# 绘制不同k值下分类准确率的散点图
plt.scatter([k] * len(accuracies), accuracies)
# 计算分类准确率均值并排序
accuracies_mean = np.array([np.mean(v) for k, v in sorted(k_to_accuracies.items())])
# 计算分类准确率标准差并排序
accuracies_std = np.array([np.std(v) for k, v in sorted(k_to_accuracies.items())])
# 绘制有质询区间的误差棒图
plt.errorbar(k_choices, accuracies_mean, yerr=accuracies_std)
# 绘图标题
plt.title('Cross-validation on k')
# x轴标签
plt.xlabel('k')
# y轴标签
plt.ylabel('Cross-validation accuracy')
plt.show()
if __name__ == '__main__':
# 导入 KNeighborsClassifier 模块
from sklearn.neighbors import KNeighborsClassifier
# 创建 k近邻实例
neigh = KNeighborsClassifier(n_neighbors=10)
# k 近邻模型拟合
neigh.fit(X_train, y_train)
# k 近邻模型预测
y_pred = neigh.predict(X_test)
# 预测结果数组重塑
y_pred = y_pred.reshape((-1, 1))
# 统计预测正确的个数
num_correct = np.sum(y_pred == y_test)
# 计算分类准确率
accuracy = float(num_correct) / X_test.shape[0]
print(f'KNN Accuracy based on sklearn: {accuracy}.')